Principe général des tests
statistiques
Accueil
> Sommaire
> Test statistique
1
Les fluctuations aléatoires
La survenue d’un
événement clinique chez un patient est en partie
imprévisible et s’apparente donc à un
phénomène aléatoire. Pour un patient donné, il est
impossible de prévoir avec certitude la survenue ou non de
l’événement. Par
exemple, la survenue sur une période de 5 ans d'un accident
cardio-vasculaire chez un sujet hypertendu est imprévisible.
Si l’on surveille plusieurs groupes
regroupant des sujets ayant tous la même probabilité de faire
l’événement, disons 10%, les différents pourcentages
observés vont fluctuer autour de cette valeur. Comme dans ces groupes
tous les sujets ont le même risque, appelé vraie valeur
dans la terminologie statistique, ces différences observées sont
à mettre uniquement sur le compte du hasard. Ces fluctuations du
paramètre d’intérêt (ici la fréquence de
survenue de l’événement clinique) observées entre
différents échantillons et dues entièrement au hasard sont
appelées fluctuations aléatoires d’échantillonnage.
|
Figure 1 – Parmi 4 groupes de patients ayant la même probabilité p (appelée aussi risque) de faire l'événement, les pourcentages d’événements observés varient d'un groupe à l'autre Ces différences sont dues au hasard et sont appelées fluctuations aléatoires d’échantillonnage. |
|
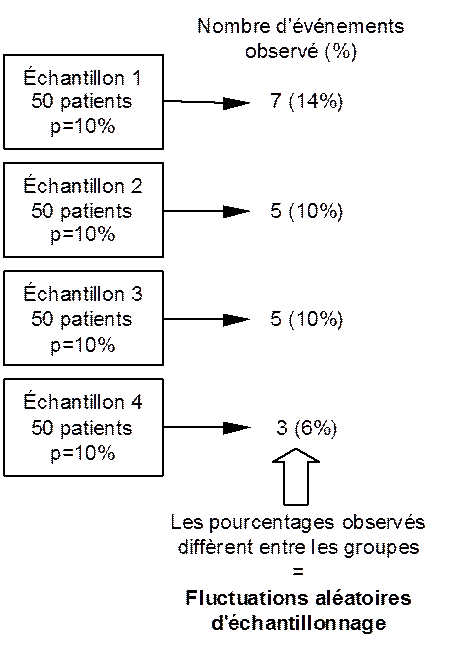
2
Les erreurs statistiques
Les fluctuations aléatoires d’échantillonnage ont des conséquences sur la comparaison de deux groupes (à la recherche d’une différence numérique dans le paramètre considéré). Elles peuvent, entre autres, faire apparaître entre les groupes une différence qui en réalité n’existe pas. Dans une situation où le risque est identique dans les 2 groupes, par hasard, le pourcentage observé dans un groupe pourra être inférieur à ce qu’il aurait du être tandis que dans l’autre groupe, le hasard conduit à une valeur observée surestimant la vraie valeur. Par cette double action du hasard en sens contraire, apparaît une différence entre les deux pourcentages observés alors qu’en réalité ils auraient du être identiques puisque les patients des deux groupes ont tous le même risque.
Le but pratique de la comparaison est de conclure, à partir de l’observation, sur l’existence (ou non) d’une vraie différence entre les deux groupes. Comme la réalité est inconnue, l’observation d’une différence apparente va faire conclure, à tort, à l’existence d’une différence vraie entre ces deux groupes. Dans l’essai thérapeutique, la constatation d’une différence suggère l’existence d’un effet non nul du traitement.
Ainsi les fluctuations aléatoires sont susceptibles de conduire à des conclusions erronées à partir de l’observation. L’observation fait conclure à l’existence d’une différence qui, en réalité, n’existe pas. Il s’agit d’une erreur statistique car elle est induite par les fluctuations aléatoires. Elle est appelée erreur statistique de première espèce, ou erreur alpha.
Dans un essai thérapeutique, l’erreur alpha est de conclure à l’efficacité d’un traitement qui, en fait, est inefficace.

Figure 2 – Illustration du mécanisme conduisant à l’erreur statistique alpha
À
l’opposé, les fluctuations aléatoires peuvent aussi faire
disparaître une différence qui existe pourtant. Lors de la
comparaison d’un paramètre d’intérêt entre deux
groupes pour lesquels il existe une réelle différence, le hasard
peut conduire à ce que les observations se rapprochent les unes des
autres, annulant ainsi
Dans un essai thérapeutique, l’erreur statistique bêta fait courir le risque de ne pas mettre en évidence l’efficacité d’un traitement.
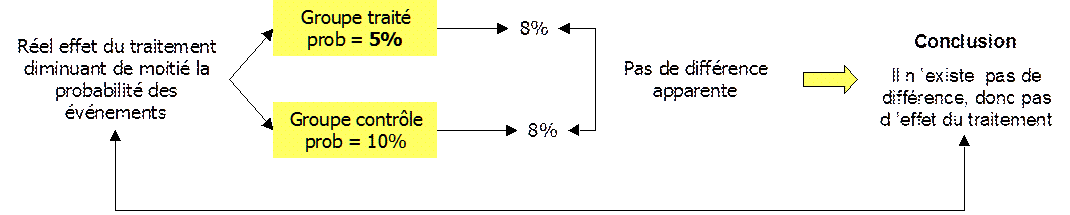
Figure 3 – Illustration du mécanisme conduisant à l’erreur statistique beta
3
Le test statistique
Il découle de ce que nous venons de voir concernant l’erreur statistique alpha que devant une différence observée il existe deux possibilités : 1) cette différence est uniquement due au hasard et en réalité elle n’existe pas ; 2) cette différence observée est la conséquence directe d’une réelle différence entre les deux groupes.
Les comparaisons sont effectuées pour chercher à faire des conclusions à partir des observations. Dans l’essai thérapeutique, on cherche à conclure ou non à l’efficacité du traitement utilisé en comparant les résultats obtenus dans chaque groupe. De plus ces conclusions vont être à la base de décision, dont les conséquences sont parfois très larges. A partir des conclusions d’un essai thérapeutique, on prendra ou non la décision de recommander l’utilisation d’un traitement.
S’il n’existait aucun moyen de faire la part des choses entre ces deux possibilités, aucune conclusion et décision ne seraient possibles en pratique. Un risque d’erreur inconnu serait constamment présent, laissant planer un doute sur toute conclusion. La solution à ce dilemme est apportée par le test d’hypothèse.
Le test statistique est un moyen qui permet de rechercher s’il existe une réelle différence entre 2 groupes
Devant une différence observée, le test statistique permet de calculer la probabilité que l’on aurait d’observer ce résultat si en réalité il n’y avait pas de différence entre les deux groupes. Cette probabilité est appelée p. Avec un peu moins de rigueur, il est possible de dire qu’elle correspond à la probabilité que la différence observée soit due au hasard en l’absence d’effet du traitement. Elle permet ainsi une quantification du risque de faire une erreur de première espèce si l’on décidait de conclure à l’existence d’une différence entre les deux groupes.
En pratique, on avancera effectivement cette conclusion que si le risque que l’on a de se tromper est suffisamment petit. Classiquement, il a été convenu que le risque acceptable d’erreur alpha est de 5%. Ainsi, devant une différence observée, on conclura à l’existence d’une réelle différence seulement si le risque de se tromper pris en faisant cette conclusion est inférieur à 5%, c’est-à-dire, si la valeur de p donnée par le test est inférieure au seuil de 5%.
Le test statistique est donc un moyen de contrôler le risque d’erreur alpha. Il ne prend pas directement en compte le risque d’erreur bêta.
Le risque alpha est le risque numérique (probabilité) de commettre une erreur statistique alpha. Le risque bêta est celui de commettre une erreur bêta.
4
La signification statistique
Lorsque p≤5%, la différence
est dite « statistiquement significative ». C'est-à-dire
qu'elle est suffisamment importante par rapport aux fluctuations
aléatoires pour que sa probabilité d’être
observée en l'absence de réelle différence soit
inférieure au seuil préalablement choisi de 5% (seuil de la
signification statistique).
Quand p>5%, la différence
n’est pas « statistiquement significative ». En
simplifiant, « elle n’est pas suffisamment importante par
rapport aux fluctuations aléatoires pour pouvoir raisonnablement exclure
qu’elle soit un artefact dû au hasard ». Une
différence non significative n’est pas synonyme d’absence
d’effet. La comparaison est peut-être insuffisamment puissante pour
mettre en évidence la différence qui existe. L’absence de
preuve n’est pas la preuve de l’absence. Le problème du
risque bêta et de la puissance statistique sera envisagé dans une
autre rubrique.

Figure 4 – Principe du test statistique
Un résultat statistiquement significatif signifie seulement que le risque d’erreur alpha est faible, il ne signifie pas qu’il n’y a aucun risque d’erreur et que la conclusion que l’on fait est une certitude. Avec un seuil de 5%, avec un résultat significatif il reste encore 5% de risque de se tromper.
5
Un seuil de risque α de 5%
est-il acceptable ?
Classiquement le seuil de la signification statistique est fixé
à 5%. Une autre valeur peut être utilisée, en particulier
plus contraignante, comme 1%. En effet, un risque de 5% n’est pas
totalement négligeable. Par exemple, supposons qu’il existe
environ 400 spécialités différentes dans la
pharmacopée et que chacune n’a été
évaluée que par un seul essai thérapeutique. Avec un
risque alpha de 5%, 20 de ces produits seraient présents à tort
dans notre arsenal thérapeutique.
Avec un traitement qui sera très largement diffusé, comme un vaccin par exemple, prendre un risque de conclure à tort à son efficacité de 5% est trop important. Un risque de 1% serait le bienvenu. Par contre, avec une maladie très rare pour laquelle aucun traitement efficace n’est encore disponible, consentir un risque alpha de 10% est peut être envisageable.
Il est difficile de définir des normes pour le choix du seuil de la signification statistique. Il s’agit d’un choix de valeur. L’important est de se souvenir de la signification de ce choix et du fait que la valeur habituelle de 5% est arbitraire et qu’elle n’est pas immuable. Le choix d’une autre valeur plus restrictive est tout à fait possible.
6
Faut-il un ou deux essais ?
Un seuil de signification inférieur à 5% est de plus en plus utilisé dans les essais thérapeutiques comme par exemple dans l’essai HPS 1 qui comparaient la simvastatine au placebo dans la prévention des maladies cardiovasculaires chez des patients à haut risque. Cet essai de morbi-mortalité de grande taille a choisi un seuil de signification statistique de 1% en partie car il avait de forte chance d’être unique.
En effet, deux essais sont en général demandés pour apporter la preuve de l’efficacité. Cette redondance diminue le risque de conclusion globale erronée. Avec deux essais significatifs à 5%, le risque de conclure à tort à l’efficacité est de 5%*5%=0.25%. Cette règle des deux essais représente donc, entre autre, un moyen de réduire le risque d’erreur de première espèce, sans exiger un seuil de signification pour chaque essai plus strict que la valeur « habituelle » de 5%.
Cependant dans le cas où la recherche de l’effet nécessite de très nombreux patients (plusieurs milliers), il est difficile de réaliser deux essais. Dans ce cas, il est fortement souhaitable que l’essai unique qui est réalisé adopte un seuil de signification plus petit que 5% ; 2.5‰ dans l’idéal ce qui serait équivalent à la réalisation de 2 essais ; 1% au minimum (comme HPS).
7
Approche formelle du test d’hypothèse
Le test statistique cherche à départager deux hypothèses, l’une appelée hypothèse nulle (H0) et l’autre hypothèse alternative (H1). Dans un essai thérapeutique, l’hypothèse nulle correspond à l’absence d’effet du traitement étudié. L’hypothèse alternative est l’hypothèse que l’on cherche à « prouver » : l’effet du traitement n’est pas nul.
Ainsi dans un essai, on recherche l’effet d’un traitement en comparant deux proportions de survenue d’événements P1 et P0 :
·
H0 : P1
= P0
·
H1 : P1
≠ P0
Il existe deux risques d’erreur attachés au choix de H1 ou de H0. Il est ainsi possible d’accepter H1 alors que H0 est vraie (résultat faux positif) ou d’accepter H0 alors que H1 est vraie (résultat faux négatif).
· α = Pr( accepter H1 si H0 est vraie) faux positif
·
β = Pr( accepter H0
si H1 est vraie) faux négatif
Alors que l’hypothèse nulle est unique, l’hypothèse alternative correspond à une infinité de situations P1-P0 = Δ où Δ peut prendre n’importe quelle valeur. Le risque b ne peut donc être déterminé que pour une certaine valeur de D, correspondant à une hypothèse H1 particulière.
Le départage des hypothèses se fait à l’aide d’une valeur, noté p, déterminée à partir des données observées. La valeur p est la probabilité d’observer des résultats au moins aussi en désaccord avec l’hypothèse nulle que ceux qui ont été effectivement notés. Ainsi p chiffre le degré de désaccord existant entre l’observation et l’hypothèse nulle.
À partir de la valeur de p calculée, le choix final de l’hypothèse se base sur la règle suivante :
· Si p ≤ α, H0 est rejetée et H1 est acceptée.
· Si p > α, aucune conclusion n’est faite (en particulier H0 n’est pas accepté car il n’est pas possible de contrôler le risque d’erreur bêta).
8
Interprétation erronée
du p ou d’un test
significatif
Les tests statistiques et le degré de signification p font souvent l’objet
d’interprétations erronées 2.
Ainsi, on dit fréquemment à l’issue d’un test
de comparaison des moyennes statistiquement significatif qu’il y a 95% de
chance pour que les moyennes des deux groupes diffèrent. En réalité,
une telle affirmation n’a aucun sens puisque les moyennes des populations
sont des constantes et non des variables aléatoires. La
probabilité p n’est
pas relative à la différence entre les moyennes
considérées mais bien au jugement que l’on émet au
sujet de l’égalité de ces moyennes. Tout ce que l’on
peut dire, en concluant à l’existence d’une
différence avec un test statistiquement significatif, c’est que
l’on a 5 chances sur 100 seulement d’aboutir à une telle
conclusion par le simple fait du hasard.
En toute rigueur, il n’est pas possible non plus de dire que la
valeur de p représente la
probabilité que les résultats de l'essai soient dus à
Ce n’est pas non plus la probabilité de l’absence de
différence. La valeur de p est la
probabilité d’observer un résultat en l’absence de
différence, ce n’est pas la probabilité qu’il
n’y ait pas de différence compte tenu du résultat
observé. Il est donc inexact de dire que le degré de
signification p mesure la
probabilité d’absence de différence.
Tableau 1
– Interprétations erronées du p
|
le p n’est pas |
le p est |
|
p n’est pas la probabilité de
l’hypothèse nulle |
p est la probabilité d’obtenir le
résultat observé si l’hypothèse nulle est vraie |
|
p n’est pas la probabilité
d’absence de différence |
p est la probabilité d’observer une
différence au moins aussi importante si en réalité il
n’y a pas de différence |
|
p n’est pas la probabilité que le
traitement n’ait pas d’effet |
p est la probabilité d’obtenir le
résultat qui a été observé si le traitement est
en réalité inefficace |
|
p<0.05% ne signifie pas qu’il y a moins
de 5% de chance que le traitement soit sans effet |
il y a moins de 5% d’observer le
résultat obtenu si le traitement est sans effet |
|
p n’est pas Pr(H0) ou 1-Pr(H1) p n’est pas la probabilité de
l’hypothèse nulle |
p = Pr(résultat/H0) p est la probabilité conditionnelle du
résultat sous l’hypothèse nulle |
9
Alpha et bêta vus comme des taux de filtration
Le test
statistique peut être vu comme un filtre que l’on utilise pour
extraire de l’ensemble des résultats produits par les essais cliniques
ceux que l’on retiendra comme argument de l’efficacité des
traitements évalués.
Ce filtre laisse passer α% des résultats produits avec un traitement sans effet (ce qui peut être vu comme un taux de filtration de α% des faux positifs) et 1-β% des résultats produits avec un traitement efficace (soit un taux de filtration de 1-β% des vrais positifs).
Ainsi un risque alpha de 5% signifie que 5% des essais réalisés avec un traitement sans effet sera finalement retenu comme argument de l’efficacité du traitement testé. Une puissance de 80% signifie que 80% des essais réalisés avec un traitement ayant l’efficacité attendue sera retenu comme preuve de l’efficacité du traitement.
Le nombre
de faux positifs retenus à l’issu de cette procédure
dépend donc du taux de filtration alpha mais aussi de la quantité
de résultats issus de traitement sans effet que l’on a soumis
à
Si dans
l’ensemble de résultats que l’on passe par le filtre du test
statistique, il y a p% de résultats issus d’un traitement ayant
l’efficacité attendue et 1-p% de résultats obtenus avec un
traitement sans effet, a l’issu de la filtration nous aurons 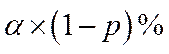 de
faux positifs et
de
faux positifs et 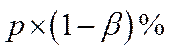 de
vrais positifs.
de
vrais positifs.
En termes
de probabilité, après avoir obtenu un résultat qui passe
le filtre (c’est à dire statistiquement significatif), la
probabilité que le traitement ai l’efficacité attendue est
égale à 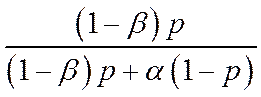 , p étant dans ce cas la
probabilité a priori que le traitement soit efficace.
, p étant dans ce cas la
probabilité a priori que le traitement soit efficace.
Ce raisonnement est identique à celui que l’on peut faire en faisant le parallèle entre tests statistiques et tests diagnostiques (cf. infra).
10 Bibliographie
1. MRC/BHF Heart Protection Study of cholesterol lowering with simvastatin in 20,536 high-risk individuals: a randomised placebo-controlled trial. Lancet 2002;360(9326):7-22.
2. Sterne JAC, Davey Smith G. Sifting the evidence—what's wrong with significance tests? BMJ 2001;322:226-31.
11 Ressources WEB
Study design and choosing a statistical test (http://bmj.bmjjournals.com/statsbk/13.shtml )
Elementary Concepts in Statistics (http://www.statsoft.com/textbook/esc.html )
Sampling
distribution (http://www.ruf.rice.edu/~lane/stat_sim/sampling_dist/index.html )
Interprétation
des essais cliniques pour la pratique médicale
www.spc.univ-lyon1.fr/polycop
Faculté de Médecine Lyon - Laennec
Mis à jour : aout 2009